「ゼロから作るDeep Learning 2 ―自然言語処理編」のRNNコード、P216、第5章「5.5.3 RNNLMの学習コード」をGRUコードに変更する。
”「ゼロから作るDeep Learning 2 ―自然言語処理編」のRNNコードを全体が見えるようにする” で作ったコードを、LSTM同様、まんまGRUに変更します。
実際のコードがこちら。
# ゼロから作る Deep Learning2のP216、第5章「5.5.3 RNNLMの学習コード」でコード全体が見えるようにできるだけ「import」を外したコード これをGRU用に変更
# coding: utf-8
import sys
sys.path.append('C:\\kojin\\資料\\AI関連\\ゼロから作る Deep Learning\\ゼロから作る Deep Learning2\\deep-learning-from-scratch-2-master\\')
import matplotlib.pyplot as plt
import numpy as np
# from common.optimizer import SGD
from dataset import ptb # このimportを有効にするには上記パス設定「sys.path.append('C:\\kojin\\AI関連\\・・・」が必要!
# from simple_rnnlm import SimpleRnnlm
# ハイパーパラメータの設定
batch_size = 10
wordvec_size = 100
hidden_size = 100
time_size = 5 # Truncated BPTTの展開する時間サイズ
lr = 0.2
max_epoch = 100
# 学習データの読み込み(データセットを小さくする)
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_size = 1000
corpus = corpus[:corpus_size]
vocab_size = int(max(corpus) + 1)
xs = corpus[:-1] # 入力
ts = corpus[1:] # 出力(教師ラベル)
data_size = len(xs)
# 学習時に使用する変数
max_iters = data_size // (batch_size * time_size)
time_idx = 0
total_loss = 0
loss_count = 0
ppl_list = []
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# コード変更、追加箇所の「開始」部分
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# GPUを定義しておく(コードのどこかでこの定義を参照しているらしいけど、PCにNVIDIA無いので、下記定義をするだけ)
GPU = False
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# functions.py の抜粋「開始」部分
# ---------------------------------------------------------------------------------------------------------------------------
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
# ---------------------------------------------------------------------------------------------------------------------------
# functions.py の抜粋「終了」部分
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# optimizer.py の抜粋「開始」部分
# ---------------------------------------------------------------------------------------------------------------------------
class SGD:
'''
確率的勾配降下法(Stochastic Gradient Descent)
'''
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for i in range(len(params)):
params[i] -= self.lr * grads[i]
# ---------------------------------------------------------------------------------------------------------------------------
# optimizer.py の抜粋「終了」部分
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# layers.py の抜粋「開始」部分
# ---------------------------------------------------------------------------------------------------------------------------
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
# ---------------------------------------------------------------------------------------------------------------------------
# layers.py の抜粋「終了」部分
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# time_layers.py の抜粋「開始」部分 下記のコードは「RNN」部分を「GRU」に置き換えたもの
# ---------------------------------------------------------------------------------------------------------------------------
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class GRU:
def __init__(self, Wx, Wh, b):
'''
Parameters
----------
Wx: 入力`x`用の重みパラーメタ(3つ分の重みをまとめる)
Wh: 隠れ状態`h`用の重みパラメータ(3つ分の重みをまとめる)
b: バイアス(3つ分のバイアスをまとめる)
'''
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
bz, br, bh = b[:H], b[H:2 * H], b[2 * H:]
z = sigmoid(np.dot(x, Wxz) + np.dot(h_prev, Whz) + bz)
r = sigmoid(np.dot(x, Wxr) + np.dot(h_prev, Whr) + br)
h_hat = np.tanh(np.dot(x, Wxh) + np.dot(r*h_prev, Whh) + bh)
h_next = (1-z) * h_prev + z * h_hat
self.cache = (x, h_prev, z, r, h_hat)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
x, h_prev, z, r, h_hat = self.cache
dh_hat =dh_next * z
dh_prev = dh_next * (1-z)
# tanh
dt = dh_hat * (1 - h_hat ** 2)
dbh = np.sum(dt, axis=0)
dWhh = np.dot((r * h_prev).T, dt)
dhr = np.dot(dt, Whh.T)
dWxh = np.dot(x.T, dt)
dx = np.dot(dt, Wxh.T)
dh_prev += r * dhr
# update gate(z)
dz = dh_next * h_hat - dh_next * h_prev
dt = dz * z * (1-z)
dbz = np.sum(dt, axis=0)
dWhz = np.dot(h_prev.T, dt)
dh_prev += np.dot(dt, Whz.T)
dWxz = np.dot(x.T, dt)
dx += np.dot(dt, Wxz.T)
# rest gate(r)
dr = dhr * h_prev
dt = dr * r * (1-r)
dbr = np.sum(dt, axis=0)
dWhr = np.dot(h_prev.T, dt)
dh_prev += np.dot(dt, Whr.T)
dWxr = np.dot(x.T, dt)
dx += np.dot(dt, Wxr.T)
self.dWx = np.hstack((dWxz, dWxr, dWxh))
self.dWh = np.hstack((dWhz, dWhr, dWhh))
self.db = np.hstack((dbz, dbr, dbh))
self.grads[0][...] = self.dWx
self.grads[1][...] = self.dWh
self.grads[2][...] = self.db
return dx, dh_prev
class TimeGRU:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = GRU(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
class Simple_TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
def forward(self, xs, ts):
N, T, V = xs.shape
layers = []
loss = 0
for t in range(T):
layer = SoftmaxWithLoss()
loss += layer.forward(xs[:, t, :], ts[:, t])
layers.append(layer)
loss /= T
self.cache = (layers, xs)
return loss
def backward(self, dout=1):
layers, xs = self.cache
N, T, V = xs.shape
dxs = np.empty(xs.shape, dtype='f')
dout *= 1/T
for t in range(T):
layer = layers[t]
dxs[:, t, :] = layer.backward(dout)
return dxs
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3: # 教師ラベルがone-hotベクトルの場合
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
# バッチ分と時系列分をまとめる(reshape)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask # ignore_labelに該当するデータは損失を0にする
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis] # ignore_labelに該当するデータは勾配を0にする
dx = dx.reshape((N, T, V))
return dx
# ---------------------------------------------------------------------------------------------------------------------------
# time_layers.py の抜粋「終了」部分
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# simple_rnnlm.py の抜粋「開始」部分 「GRU」コード用に書き換えた(第6章の「rnnlm.py」からclass名以外をコピーし名前変更、
# 「GRU」用に書き換えた)
# ---------------------------------------------------------------------------------------------------------------------------
class SimpleGrulm:
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 重みの初期化
embed_W = (rn(V, D) / 100).astype('f')
gru_Wx = (rn(D, 3 * H) / np.sqrt(D)).astype('f') # 「lstm」を「gru」に書き換えつつ、「4」を「3」にした
gru_Wh = (rn(H, 3 * H) / np.sqrt(H)).astype('f') # 「lstm」を「gru」に書き換えつつ、「4」を「3」にした
gru_b = np.zeros(3 * H).astype('f') # 「lstm」を「gru」に書き換えつつ、「4」を「3」にした
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# レイヤの生成 # 「TimeLSTM」を「TimeGRU」に書き換え
self.layers = [
TimeEmbedding(embed_W),
TimeGRU(gru_Wx, gru_Wh,gru_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.gru_layer = self.layers[1] # 「lstm」を「gru」に書き換え
# すべての重みと勾配をリストにまとめる
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.gru_layer.reset_state() # 「lstm」を「gru」に書き換え
# ---------------------------------------------------------------------------------------------------------------------------
# simple_rnnlm.py の抜粋「終了」部分
# +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# コード変更、追加箇所の「終了」部分
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
# モデルの生成
model = SimpleGrulm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
# ミニバッチの各サンプルの読み込み開始位置を計算
jump = (corpus_size - 1) // batch_size
offsets = [i * jump for i in range(batch_size)]
for epoch in range(max_epoch):
for iter in range(max_iters):
# ミニバッチの取得
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
for t in range(time_size):
for i, offset in enumerate(offsets):
batch_x[i, t] = xs[(offset + time_idx) % data_size]
batch_t[i, t] = ts[(offset + time_idx) % data_size]
time_idx += 1
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# エポックごとにパープレキシティの評価
ppl = np.exp(total_loss / loss_count)
# print('| epoch %d | perplexity %.2f'
# % (epoch+1, ppl))
ppl_list.append(float(ppl))
total_loss, loss_count = 0, 0
# グラフの描画
x = np.arange(len(ppl_list))
plt.plot(x, ppl_list, label='train')
plt.xlabel('epochs')
plt.ylabel('perplexity')
plt.show()
実行結果がこちら。
ちゃんと動いてそうです。
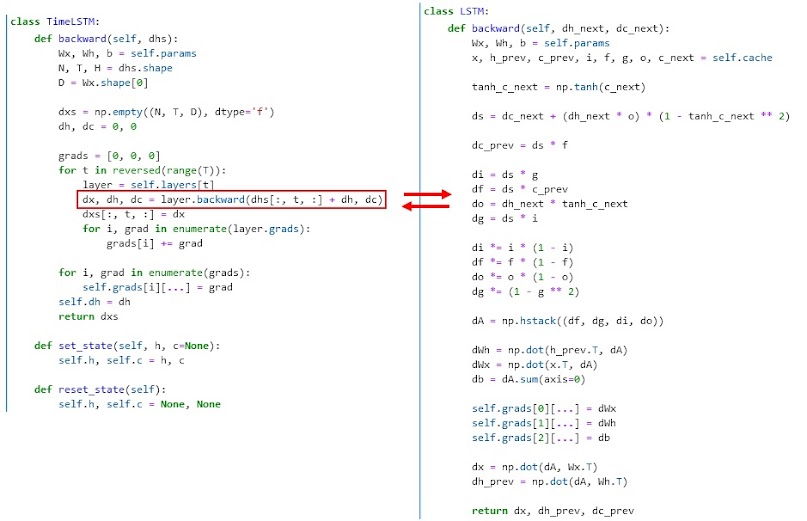
RNNからGRUへ変更するために書き換えたところはLSTMで書き換えたところと同じです。
・「functions.py」から「sigmoid()」関数を追加
・「time_layers.py」から「class GRU」と「class TimeGRU」をコピーし、「class RNN」と「class TimeRNN」と入れ替え。
「class GRU」
と
「class TimeGRU」
加えて「class SimpleRnnlm」のクラス名を「class Simplegrulm」に変更。LSTMで書き換えたところをGRU用に書き換えています。
他の部分はRNNと同じなので
”「ゼロから作るDeep Learning 2 ―自然言語処理編」のRNNコードを全体が見えるようにする”
加えて、
”「ゼロから作るDeep Learning 2 ―自然言語処理編」のRNNコード、P216、第5章「5.5.3 RNNLMの学習コード」をLSTMコードに変更する”
の2つを確認してください。
”「ゼロから作るDeep Learning 2 ―自然言語処理編」のGRUコード” に関して、
”深層学習/ゼロから作るDeep Learning2 - GRUを動かしてみる”
というサイトがあります。ゼロつく2のGRUを実装して、動かしているブログですが、多分とても貴重なサイトだと思います。もしよろしければ参照してみてください。
あと、この方の書かれている他のブログも貴重だと思いますので、下記にリンクします。
ピックアップ記事
以上です。









コメント
コメントを投稿